※ マルチ・スレッド・アンローダー及びMulti-threaded Unloaderは株式会社プラムシックスの登録商標です。
Multi-threaded Unloader(マルチ・スレッド・アンローダー)、通称「MTU(エムティーユー)」は大量データでも快適に扱えるオラクル専用の高速アンロード・ユーティリティーです。
秒速270万件を超こえる圧倒的なパワーでデータ移動に関するソリューションを具体化するのに役立てる事が出来ます。

Oracle Database サーバーへのローカル接続はもちろんリモート接続も可能
バルグフェッチと低水準なメモリー操作の融合により効率的なデータ処理を実現

与えられたCPUリソース量のままに処理能力がスケール・アウト

データを再アップロードする時に便利なスクリプトや制御ファイルを自動生成
【MTUの機能】

【MTUの特長】
MTU及びMTU Advanceに関するオリジナル動画のご紹介コーナーです。
MTU 紹介ムービー ~製品紹介編~(再生時間:3分17秒)
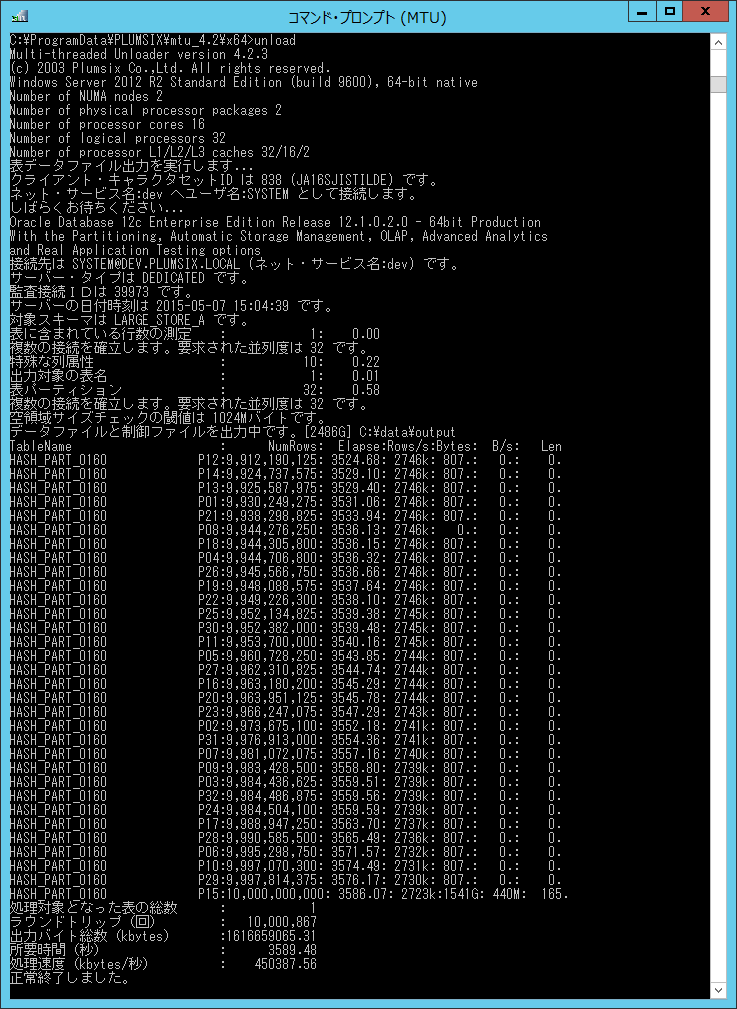
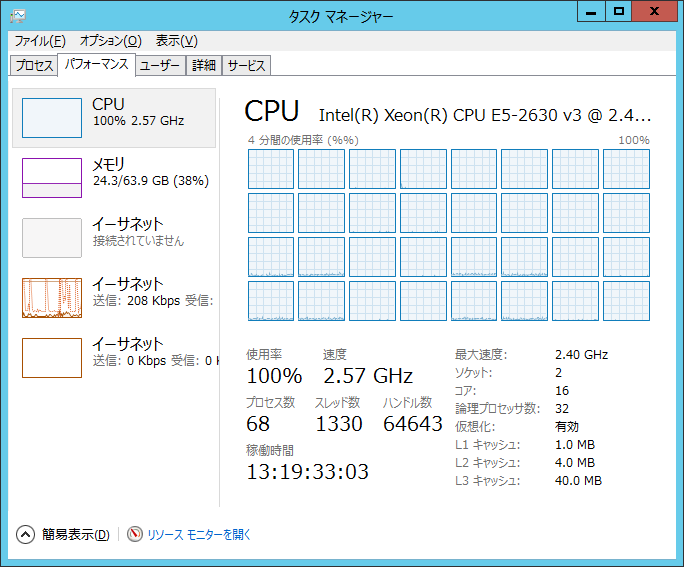
弊社テスト環境にて100 億行を含むパーティション表の全件を60 分でアンロードすることができました。
(平均データ長165Byte、CSVファイルのサイズは約1.5TB)
【テスト環境】
| CPU | IntelR XeonR E5-2630v3 8コア/ 2.4GHz 2次キャッシュメモリ20MB ×2個 |
|---|---|
| RAM | 64GB (8GB 2133 RDIMM ×8個) |
| HBA | アレイコントローラ、キャッシュ2GB SAS 12Gbps /PCI Express 3.0 |
| ストレージ | 内蔵2.5インチSAS HDD-900GB(10krpm)×6個 内蔵2.5インチSAS HDD-1.2TB(10krpm)×4個 |
| OS | WindowsR ServerR 2012 R2 Standard |
| RDBMS | OracleR Database 12c Release 1 (12.1.0.2.0) – Enterprise Edition Microsoft Windows x64 |
ここではMTUの基本機能である[アンロード機能]と[クエリ機能]、そしてデータ加工プログラムへのデータ供給をより高速化する[名前付きパイプ機能]をご紹介します。
[アンロード機能]は、内部的に select * from <table_name> にあたるSQL文が自動生成され、テーブルに含まれるすべての行データの集合(=フルセット)をデータファイルへ出力します。
※<table_name> にあたる部分は、表セグメントかパーティション表に限定されます。
[アンロード機能]では全ての行データのオフライン・コピーを、DBサーバのストレージ以外の場所へ保存出来るので、Oracleデータベースの論理バックアップとしてもご利用いただけます。
しかし、[アンロード機能]は式・結合・選択・集計・選択リスト・整列を含む問合せ結果や、シノニム・マテリアライズドビュー・通常のビュー・リモート問合せの結果を戻すことはできません。このような用途では[クエリ機能]か[データ加工プログラム]をご利用ください。
更にSQL*Loaderの制御ファイルと、それを使って抽出済みのフラットファイルデータを再ロードする事が出来るSQL*Loaderのコマンド呼出しを含んだシェルスクリプトを自動生成する事も可能です。

[クエリ機能]は[アンロード機能]と異なり、SQL(Select文)をユーザー様が任意に記述できます。SQL Select文で表現可能なあらゆる問い合わせ結果をデータファイルに出力可能です。
※ [クエリ機能]は[アンロード機能]に不足している使い勝手の柔軟性を補う補助的な機能です。
[クエリ機能]を使用すると、式・結合・選択・集計・選択リスト・整列を含む問合せ結果や、シノニム・マテリアライズドビュー・通常のビュー・リモート問合せの結果を戻すことができます。
また、プレースフォルダを含むSQLに対してバインド入力変数を定義することもできるので、一度記述したSQLを変更せずに条件の値だけ変えて問合せを再実行できます。
<注意点>他のツールで性能が良くない問合せをMTUの[クエリ機能]を使って実行しても、結果は変わりません。MTUの利用が有利に働くのは、戻されるデータ量が著しく多い場合です。

MTUの抽出データ出力先として、データファイルの他に[名前付きパイプ]を選択できます。
[名前付きパイプ]はプロセス間通信の手法の一つです。ソケットのような異機種間を超える接続性はありませんが、無手順で同じOS環境内のプロセス同士の通信を高速にやり取りする事が可能です。
この機能を使用すると、MTUからデータ加工プログラムへのダイレクト通信が可能となります。「中間ストレージ消費ゼロ! I/O待機時間ゼロ!」データファイルを経由した場合と比べ、より高速な処理を実現できます。
また、それぞれのプログラムは独立して動かせるため、CPUパワーを集中させることで待機時間の短縮に繋がります。
データ加工プログラムには、製品パッケージにバンドルされたもの以外にも、一般に入手できる・あるいはお客様ご自身が開発された、標準入力(stdin)をサポートするプログラムを使うことができます。
当サイト内の下記リンクでは、Java言語で作られた標準入力をサポートするプログラム(ソースコード付き)をデータ加工プログラムとして繋げる事で、名前付きパイプ機能の汎用的な使い方をご紹介しています。
http://mtu-accelerates.jp/wp/java_with_ipc
MTUが出力したデータファイルは、データ加工プログラムへ供給するだけではなく、加工せずにユーザー様がそのまま利用することも可能です。具体的な用途としては以下のようなものが考えられます。
物理バックアップのみでは回復が困難なプログラムのバグやヒューマンエラーによるデータ消失に対する備え
限られた時間内での速やかなデータ移動(精度の高い所要時間見積もり)
条件を変えて繰り返しテストするためにデータセットの容易な巻き戻しが可能
ビッグデータの時代を迎え、日々大量データを扱う大手企業様や団体様を中心に広くご活用いただいております
63 社 295 ライセンス
※2020年1月時点、MTUとMTU Advanceの実績合計