※ 簡単に言えば、Oracle専用の高速データ抽出(Extraction)・加工(Transformation)ツールです。
出力したデータファイルは BIツール・帳票作成ツール・EXCEL・業務システム・各種パッケージなど、様々なソフトウェアとの効率的なデータ連携にご利用いただけます。 Oracleデータベースに大容量データを保有していて、その利活用に”課題”を抱えているお客様、是非一度MTU Advanceのパワーを実際にご体感ください。
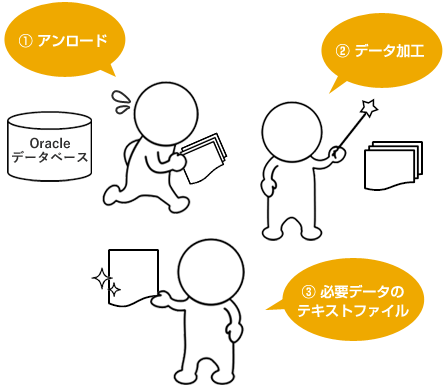
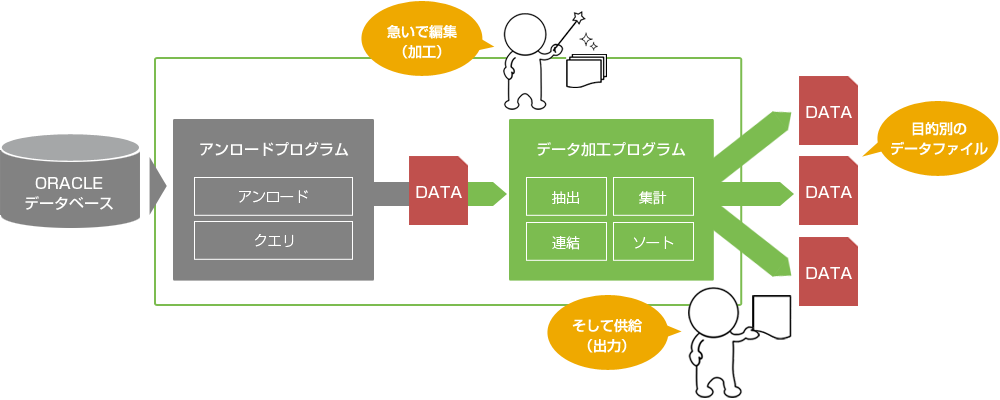
MTU Advanceは、大きく分けて [アンロードプログラム] と [データ加工プログラム] の二つで構成されております。
[アンロードプログラム] がOracleデータベースに接続して指定データの高速抽出処理を、[データ加工プログラム] が抽出データに対して任意に設定した高速データ加工処理を実行します。 尚、Oracleデータベースの論理バックアップなど、データ加工処理が必要ない用途では [アンロードプログラム] のみを使用する事も可能です。
当ページでは二つのプログラムについて、主だった<特長>と<機能>をご紹介いたします。
ここに掲載する以外にも魅力的な機能が沢山ございますので、下記フォームよりお気軽にお問い合わせください。
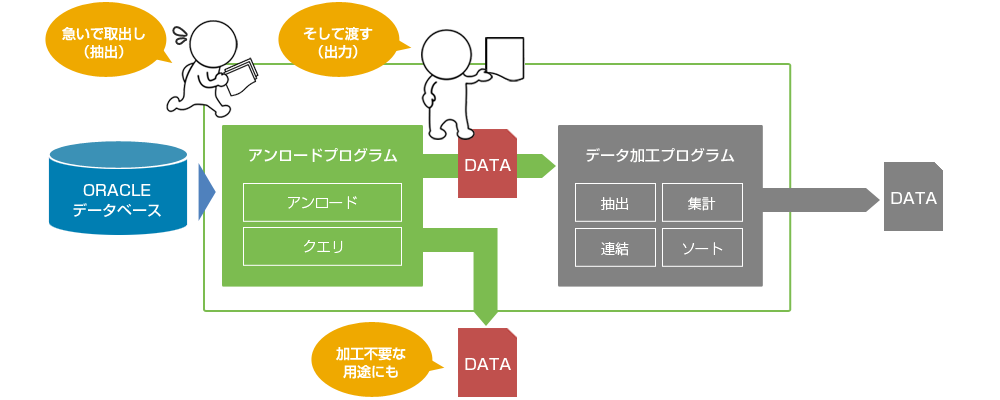
MTU Advanceのアンロードプログラムは、Oracleデータベースから任意のデータを超高速に抽出し、テキスト形式のデータファイルへ出力するアンロード処理*1を行います。 簡単に言ってしまえば、「とにかく早くOracleデータベースからデータを抽出して、データ加工プログラムへ供給する」役割を果たします。
*1 アンロードとは? : 他のDBやアプリケーションで使用するため、データを外部テキストファイルにコピーする作業を指します。
● 出力可能なデータファイル形式
COMP-3など固定長データ形式や、CSV、TSVなどの可変長データ形式も選択可能です。 ※データ加工プログラムとは異なります。
アンロード処理は、[接続先DB]と抽出対象の[テーブル名]を指定するだけで、コマンドで簡単に実行できます。この際、ユーザーは任意の並列度を指定可能、マルチコアシステムのCPUを集中投下する事でアンロード処理の所要時間を大幅に短縮します。
また、アンロードプログラムが出力したデータファイルは、データ加工プログラムへ供給するだけではなく、加工せずにユーザー様がそのまま利用することも可能です。具体的な用途としては以下のようなものが考えられます。
物理バックアップのみでは回復が困難なプログラムのバグやヒューマンエラーによるデータ消失に対する備え
限られた時間内での速やかなデータ移動(精度の高い所要時間見積もり)
条件を変えて繰り返しテストするためにデータセットの容易な巻き戻しが可能
10,000,000,000行(100億行)のデータをたったの60分で抽出!
| CPU | Intel® Xeon® E5-2630v3 8コア/ 2.4GHz 2次キャッシュメモリ20MB ×2個 |
|---|---|
| RAM | 64GB (8GB 2133 RDIMM ×8個) |
| HBA | アレイコントローラ、キャッシュ2GB SAS 12Gbps /PCI Express 3.0 |
| ストレージ | 内蔵2.5インチSAS HDD-900GB(10krpm)×6個 内蔵2.5インチSAS HDD-1.2TB(10krpm)×4個 |
| OS | Windows® Server® 2012 R2 Standard |
| RDBMS | Oracle® Database 12c Release 1 (12.1.0.2.0) – Enterprise Edition Microsoft Windows x64 |
最大の特長は、何と言ってもアンロード処理の超高速性能です。
マルチスレッドや非同期ファイル操作といった高速化技術が応用され、マルチプロセッサシステムの能力を最大限引き出すことのできる設計となっています。
弊社テスト環境(詳細は右図参照)にて、100億行を含むパーティション表の全件をたった60分でアンロードしました。(行平均データ長165バイト、CSVファイルのサイズは約1.5TB)
この高速性能をいかし、ETLツール*2としてのデータマート作成や、データベースの論理バックアップ作成等々、多くの企業様にご活用いただいております。
*2 ETLとは? : 蓄積されたデータを抽出(Extract)し、利用しやすい形に加工(Transform)して、書き出す(Load)こと。ETLツールはその支援ソフトウェアを指す。
MTU AdvanceはOracle専用、特化した設計だから実現した「超」高速性能
一般的なETLツールは、Oracleデータベース以外にもMicrosoft SQL ServerやIBM DB2など、様々なDBに対応しています。これに対し、MTU AdvanceのアンロードプログラムはOracleデータベースに特化した設計となっておりますので、理論的限界に近い速度の実現が可能なのです。
以下、「超」高速性能を実現したアンロードプログラムの具体的な技術の一部をご紹介いたします。
アンロードプログラムの基本機能である[アンロード機能]と[クエリ機能]、そしてデータ加工プログラムへのデータ供給をより高速化する[名前付きパイプ機能]をご紹介します。
[アンロード機能]は、内部的に select * from <table_name> にあたるSQL文が自動生成され、テーブルに含まれるすべての行データの集合(=フルセット)をデータファイルへ出力します。
※<table_name> にあたる部分は、表セグメントかパーティション表に限定されます。
[アンロード機能]では全ての行データのオフライン・コピーを、DBサーバのストレージ以外の場所へ保存出来るので、Oracleデータベースの論理バックアップとしてもご利用いただけます。
しかし、[アンロード機能]は式・結合・選択・集計・選択リスト・整列を含む問合せ結果や、シノニム・マテリアライズドビュー・通常のビュー・リモート問合せの結果を戻すことはできません。 このような用途では[クエリ機能]か[データ加工プログラム]をご利用ください。

[クエリ機能]は[アンロード機能]と異なり、SQL(Select文)をユーザー様が任意に記述できます。SQL Select文で表現可能なあらゆる問い合わせ結果をデータファイルに出力可能です。
※ [クエリ機能]は[アンロード機能]に不足している使い勝手の柔軟性を補う補助的な機能です。
[クエリ機能]を使用すると、式・結合・選択・集計・選択リスト・整列を含む問合せ結果や、シノニム・マテリアライズドビュー・通常のビュー・リモート問合せの結果を戻すことができます。
また、プレースフォルダを含むSQLに対してバインド入力変数を定義することもできるので、一度記述したSQLを変更せずに条件の値だけ変えて問合せを再実行できます。
<注意点>他のツールで性能が良くない問合せをMTU Advanceの[クエリ機能]を使って実行しても、結果はかわりません。MTU Advanceの利用が有利に働くのは、戻されるデータ量が著しく多い場合です。
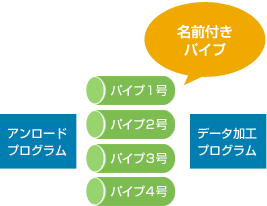
アンロードプログラムの抽出データ出力先として、データファイルの他に[名前付きパイプ]を選択できます。
[名前付きパイプ]はプロセス間通信の手法の一つです。
ソケットのような汎用性はありませんが、無手順で同じOS環境内のプロセス同士の通信を高速にやり取りすることが可能です。
この機能を使用すると、アンロードプログラムからデータ加工プログラムへダイレクト通信が可能となります。「中間ストレージ消費ゼロ! I/O待機時間ゼロ!」データファイルを経由した場合と比べ、より高速な処理を実現できます。
また、二つのプログラムは独立して動かせるため、CPUパワーを集中させることで待機時間の短縮に繋がります。
MTU Advanceのデータ加工プログラムは、アンロードプログラムが抽出したデータを簡単・高速に加工して、用途に合わせた様々な形式のデータファイルとして出力します。端的に申し上げますと、「受け取ったデータを急いで加工して、選択した形式のデータファイルを出力する」役割を果たします。
● 出力可能なデータファイル形式
CSV、XML、JSONなど、加工後の活用方法に合わせた様々な形式に変換可能。※アンロードプログラムとは異なります。
コマンドベースなので専門的なプログラミング知識は不要、データ操作に必要な条件を指定したら実行するだけです。また、従来データの結合処理のために一般的に利用されてきたJavaアプリケーションの10倍という高速化を実現、データ量に応じたリニアな高速データ加工が特長です。
MTU Advanceから高速出力した目的別データファイルは、大量データを扱う様々なソフトウェアでご活用いただけます。具体的な連携アプリケーションの例としては、以下のようなものが考えられます。
BI(ビジネスインテリジェンス)へ最新データをスピーディに供給、タイムリーな経営分析で御社のビジネスを加速します!
レポートや帳票作成ツールへのデータ供給もMTU Advanceを使えば効率的!元データの形式変更など、急なデータ変化への対応もプログラムレスで簡単スピーディ。
通常Excelでは編集が不可能な大容量データも、一度MTU Advanceで加工して、「必要なデータだけをExcelで開いてレポート作成!」こんな使い方も可能です。
大量データの加工はお任せください!
高効率化を追求した設計でデータ加工も「超」高速
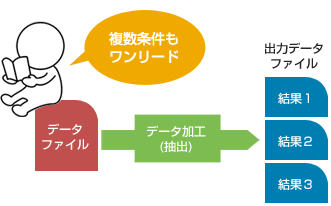
一回の処理で複数条件に合致したデータの条件仕分けが可能!
従来方式では出力ファイルの条件毎に複数回の処理(クエリ)を行っており、それぞれの処理が参照するデータソースの競合によって処理速度の遅延が発生していました。
これに対してMTU Advanceのデータ加工プログラムは、アンロードプログラムから渡されたデータをワンリード(複数条件時も一度しか読まない)で処理して結果を返します。
実際の売上集計業務への事例では、10時間にも及ぶ販売データと複数のマスタデータの結合バッチ処理をたった40分まで短縮しました。
コマンドベースで簡単、プログラムレス
開発・メンテナンスの費用を大幅削減!
コマンドベースなので、データ操作のために必要な条件を指定して実行するだけ、データは、抽出・連結・集計・ソート機能のコマンドを自由に組み合わせて加工できます。
文字列・数値・日時など、データの種類に応じた便利な関数がたくさん用意されておりますので、コマンドベースでもきめの細かいデータ加工処理を実現可能です。
※SQL文に相当する処理が実現可能、RDBに慣れた方にも容易にご利用いただけます。
抽出データをそのまま使える!
形式揃え・テーブル定義等の面倒な前処理は不要

抽出したデータの形式(項目の並び、長さなど)が異なる場合でも、データそのものに手を加える(データの形式揃え)必要はありません。 複数の業務で不揃いなデータ項目名やコードの統一も、MTU Advanceの連結機能を使って簡単に揃える事ができます。
また、運用後にデータの変化やニーズの変化があってもコマンドベースでスピーディに対応可能です。
データ加工プログラムの4つの基本機能 [抽出] [連結] [集計] [ソート] と、柔軟なデータ加工を実現する[統合コマンド]と[仮想項目機能]をご紹介します。
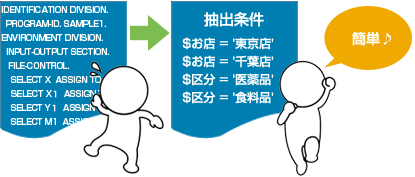
指定条件に一致するデータを抽出し、結果をデータファイルに出力します。
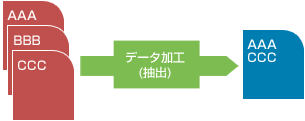
また、1回の抽出処理で複数の異なる条件を指定し、結果を別々に出力できます。
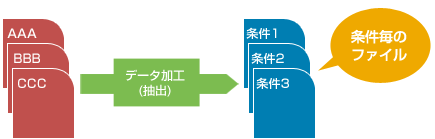
抽出時、以下の機能が有効です。
指定した連結条件に合わせて結合・編集し、結果をデータファイルに出力します。例えば、日々の業務で発生する更新履歴などのジャーナルデータと、顧客マスタ・商品マスタなど、複数のマスタデータを一度に連結できます。
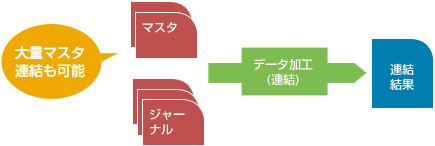
◆ INNER JOIN, LEFT OUTER JOIN, FULL OUTER JOIN に対応
連結時、以下の機能が有効です。
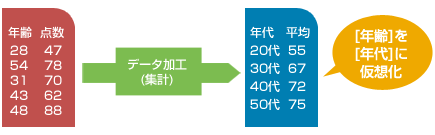
指定した軸(グループキー)に従って集計し、結果をデータファイルに出力します。 一時ファイルを使用することで、マシンの実装メモリが少ない場合でも大量データを集計できます。
◆ グループキーは階層的に複数の項目を指定できます。
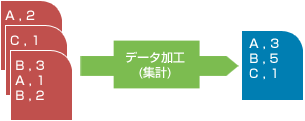
集計時、以下の機能が有効です。
指定した軸(ソートキー)に従って並び替え、結果をファイル出力します。
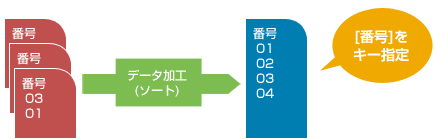
また、ソートキーを使った仕分け処理も可能です。
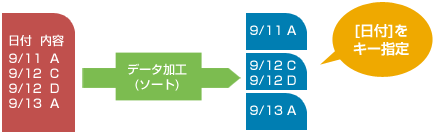
ソート時、以下の機能が有効です。
必要な機能(抽出・連結・集計・ソート)をまとめて実行できます。 処理の定義は一つのファイルに集約します。

データの値を設定した条件に基づいて別の値に変換した上で処理できます。 この機能を使用することで、より多角的な切り口でのデータ加工が可能となります。
MTU AdvanceはPL/SQL*3フリー
MTU Advanceの導入で、PL/SQLを使用しない高速データ抽出&加工を実現

Oracleデータベースを使用したプログラム開発で幅広く利用されているPL/SQL、SQL処理とロジックの両方が単一のサーバープロセスで動作可能な為、クライアント・サーバ間のラウンドトリップ量を減らせるので良好なパフォーマンスを発揮します。
一方、シングルスレッドである点(マルチスレッド不可でCPU1coreしか使用できない*4)や、DBサーバーに負荷が掛かる点など、用途によっては必要な性能を引き出すことが難しくなってしまう欠点も存在しています。
*3 PL/SQLとは? : Oracle社が、Oracleデータベースのために開発したプログラミング言語で、データベース問い合わせ言語の標準であるSQLを独自に拡張したものです。
対してMTU AdvanceはPL/SQLを使用しません、従ってPL/SQLを使ったデータ抽出及び加工処理と比べて次のようなメリットがあります。
PL/SQLは並列処理ができません。*4 一方MTU Advanceはマシンが提供する並列処理機能を制限なく使用する事が可能です。
PL/SQLはプログラミング言語です。 コマンドベースで利用可能なMTU Advanceは開発コストと時間の削減に貢献します。
リソース集約的な処理をDBとは異なるサーバで実行することで、DBサーバへの負荷を最小限に抑えられます。
PL/SQLはサーバプロセスで実行される為、サーバプロセスから見えるファイルシステムのみに出力先が限定されます。
*4 PL/SQL自体に並列プログラミングの仕様がありません、代わりにDBMS_SCHEDULERパッケージを使って非同期ジョブを複数サブミットして実現できますが、これはアンロードの本質とは異なる面での複雑さがプログラムとその運用にもたらされてしまいます。