MTUは何十GBにも達する巨大なヒープ構成表(非パーティション表)を含むスキーマから高速にデータ抽出する事が出来ます。
これを実現するのは「ヒープ構成表の並列アンロード」という新機能です。
この機能を有効化すると ROWID を基準にヒープ構成表を複数のピースへ分割し、各ピースを並列にアンロード出来るので、分割無しでアンロードする時よりも性能が大幅に向上します。
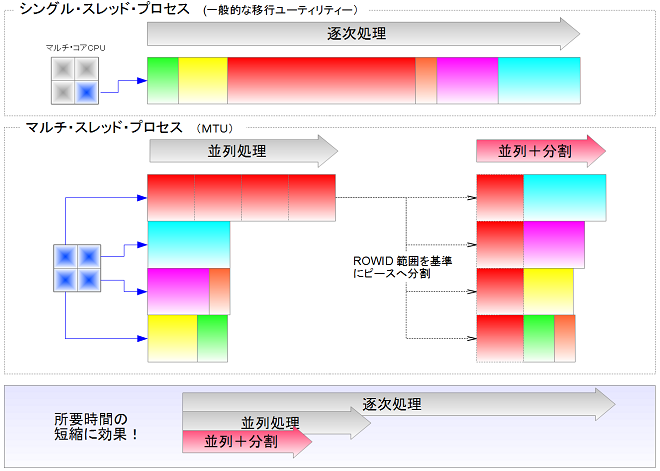
機能の概念図
テスト環境を使った実験では分割無しでアンロードする時よりも 2.2 倍高速化することが分かりました。
実験結果のサマリー
| 条件 | 所要時間 | データ率 |
|---|---|---|
| 分割無し、並列度4 | 1309 秒 | 44 MB/秒 |
| 分割数4、並列度4 | 807 秒 | 71 MB/秒 |
| 分割数8、並列度8 | 627 秒 | 95 MB/秒 |
この記事では実例を示しながら、この機能の効果的な使い方について紹介してみたいと思います。
次の表に示したヒープ構成表が含まれているスキーマを用意し、ランダムなデータを生成するツールを使い、表へ大量のテストデータを導入しました。
表によってデータ量を大きく偏らせた理由は、基幹業務系DBの実際のスキーマでも良く見かける偏り方を模擬的に表現する為です。
| テーブル名 | メガバイト | 行数 |
|---|---|---|
| TABLE_A | 23,220 | 120,000,000 |
| TABLE_B | 9,679 | 50,000,000 |
| TABLE_C | 3,904 | 20,000,000 |
| TABLE_D | 1,984 | 10,000,000 |
| TABLE_E | 1,472 | 7,500,000 |
| TABLE_F | 976 | 5,000,000 |
| TABLE_G | 200 | 1,000,000 |
| TABLE_H | 160 | 800,000 |
| 合計 | 41,595 | 214,300,000 |
テーブルの作成文は次のようなもので、TABLE_A ~ TABLE_H まですべて同じ構造です。
create table TABLE_A ( vc2_01 varchar2(30) , num_01 number(10,2) , num_02 number(10,2) , num_03 number(10,2) , vc2_02 varchar2(40) , vc2_03 varchar2(20) , num_04 number(13) , dat_01 date , vc2_04 varchar2(30) , vc2_05 varchar2(3) , vc2_06 varchar2(3) , dat_02 date , vc2_07 varchar2(3) , vc2_08 varchar2(3) , vc2_09 varchar2(3) , vc2_10 varchar2(3) , dat_03 date , vc2_11 varchar2(3) );
用意したコンピュータのスペック
| 項目 | Oracle Database サーバー用 | MTU 用 |
|---|---|---|
| CPU | Intel Xeon(R) E5420 (2.50GHz) プロセッサ数1(コア数4) |
Intel Xeon(R) X3450 (2.67GHz) プロセッサ数1(コア数4) |
| RAM | 4GB | 12GB |
| HBA | SASアレイコントローラカード | Dell SAS 6/iR Adapter Controller |
| HDD | SAS 300GB/15000rpm×5 | SAS 500GB/15000rmp×2 |
| OS | Windows Server 2003 Stardard x64 Edition |
Windows Server 2008 R2 Standard x64 Edition |
MTU を動かすコンピュータ上で Windows のパフォーマンスモニタを使ってパフォーマンス・カウンタをグラフ表示出来るようにします。
パフォーマンスモニタを設定する手順は製品に付属する「取扱説明書」の「24. 性能評価方法」の記事に従います。手順どおりに操作すると、次のパフォーマンスカウンタが設定されます。
| カウンター | スケール | 色 | 上限値 |
|---|---|---|---|
| Avg Disk bytes/Write | 0.00001 | 赤 | 10 MB/回 |
| Avg Disk sec/Write | 1000 | 緑 | 100 ミリ秒/回 |
| Avg Disk Write Queue Length | 10 | 青 | 10 個 |
| Disk Write Bytes/sec | 0.000001 | 藍 | 100 MB/秒 |
| % Processor Time | 1.0 | 黄 | 100 % |
以下に示した環境変数を除いて、まずはチューニング無しでプログラムを実行します。時間が掛かりますが、次に試す設定を決めるのに重要な手掛かりが色々と得られますので必ず実施します。
| 環境変数名 | 変更前 | 変更後 |
|---|---|---|
| USERID | SYSTEM/MANAGER | 接続先ユーザ名/パスワード@接続文字列 |
| SRC_USER | SCOTT | 対象スキーマ名 |
| BULK_SIZE | 1000 | 5000 |
| FILESIZE | 2000M | 0M |
画面表示から次の情報を得ました(一部を抜粋)。
出力バイト総数(kbytes) : 58743007.17 所要時間(秒) : 1308.92 処理速度(kbytes/秒) : 44879.08
他に、トレースファイルから次の情報を得ました。トレース・ファイルはデータファイルの出力場所と同じフォルダに _mtu_nnnnn.log (nnnnnは5桁の数字文字列)という形式の名前で出力されます。
実験ではトレースファイル中の[Order]という文字列でタグ付けされている行を抜き出して使います。
(a) (b) (c) (d)
2013-07-05 18:19:39.252 [07e8] [Order] 1: 19G (*****) TABLE_A
2013-07-05 18:19:39.252 [07e8] [Order] 2: 8200M (*****) TABLE_B
2013-07-05 18:19:39.252 [07e8] [Order] 3: 3284M (*****) TABLE_C
2013-07-05 18:19:39.252 [07e8] [Order] 4: 1643M (*****) TABLE_D
2013-07-05 18:19:39.252 [07e8] [Order] 5: 1232M (*****) TABLE_E
2013-07-05 18:19:39.252 [07e8] [Order] 6: 821M (*****) TABLE_F
2013-07-05 18:19:39.252 [07e8] [Order] 7: 164M (*****) TABLE_G
2013-07-05 18:19:39.252 [07e8] [Order] 8: 131M (*****) TABLE_H
パフォーマンスモニタから次の画像データを得ました。
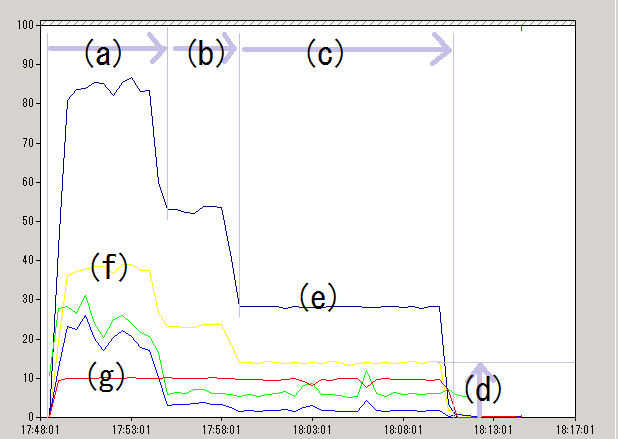
実験1のパフォーマンス・モニタ画像
次の実験では環境変数を次のように変更します。
| 環境変数名 | 変更前 | 変更後 |
|---|---|---|
| 摘要 | ||
| ROWID_SPLIT_MIN_SIZE | 0M | 10G |
| この設定はこの記事で最も重要な部分です。指定したバイト数を超えるサイズのヒープ構成表をピースへ分割して出力する指示です。ゼロを指定した場合はヒープ構成表の並列アンロードは行われません。 前の実験により、TABLE_A を単独でアンロードする時間で全体の半分以上を占めていることが判ったので、これを並列化する効果が見込まれます。トレース・ファイルの結果から表セグメントサイズが 19G バイトある事が分かったので、それを下回るが、TABLE_Bよりは大きい 10G バイトを指定します。 | ||
| PARTITIONING | 3 | 0 |
| 分割されたピースのアンロード結果を単一ファイルへまとめる場合’0’を選択します。 | ||
準備が出来たら、アンロードを開始します。
画面表示から次の情報を得ました(一部を抜粋)。
出力バイト総数(kbytes) : 58743007.17 所要時間(秒) : 807.33 処理速度(kbytes/秒) : 72762.17
パフォーマンスモニタから次の画像データを得ました。
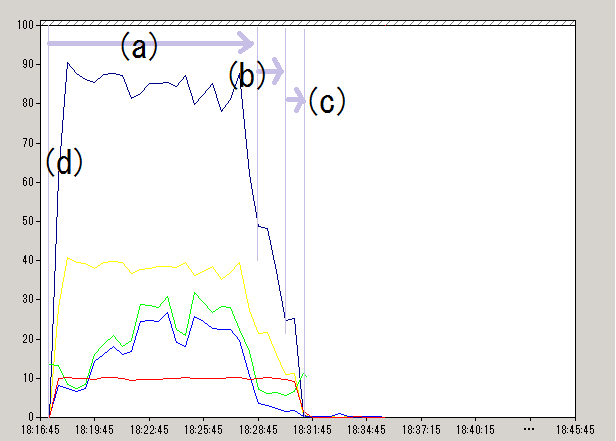
実験2のパフォーマンス・モニタ画像
次の実験では環境変数を次のように変更します。
| 環境変数名 | 変更前 | 変更後 |
|---|---|---|
| 摘要 | ||
| PARALLELISM | 4 | 8 |
| 並列度を割増して性能が良くなるかどうかは、CPU使用率:% Processor Time (黄色)を見て判断します。前回までの実験では並列度を 4 に設定しました。コンピュータの物理コア数が 4 なので並列度 4 で動作した時の最大CPU使用率は 100 パーセントになるはずですが、結果は 40 パーセント弱でした。 従って前回までの設定では CPU 以外の場所がボトルネックとなっていたと考えられ、並列度をむやみに割増しても効果は薄いと判断出来ます。しかし 40 パーセントという値から他のボトルネックを解消した後に CPU が次のボトルネックとなる可能性もあるので少しだけ割増します。 | ||
| ROWID_SPLIT_NUM_PARTS | 4 | 8 |
| セグメントのサイズが1位と2位以下で2倍以上の格差がある場合、並列度と同じ値に設定します。この設定を行うと1位の表のアンロードにすべてのスレッドが動員されるので、結果的に2位以下の表のアンロード開始を待たせて置くことが可能になります。 | ||
| ROWID_SPLIT_MIN_SIZE | 10G | 3G |
| TABLE_A, TABLE_B, TABLE_C は特にセグメントサイズが大きいのでこの3つを並列化の対象とする為の値にします。むやみに低い値を設定すると、ピースの数が増え過ぎてファイル・クローズ時のシリアル化により、却ってスロー・ダウンする事があります。 | ||
| BIND_SIZE | 20M | 200M |
| 次に説明するOVERLAP_BUFFER_LENGTHを割増す結果、メモリ不足となるので補充します。目安としては PARALLELISM×OVERLAP_BUFFER_LENGTH+20M で見積もります。 | ||
| OVERLAP_BUFFER_LENGTH | 1M | 4M |
| サーバー用のコンピュータに使われるHDDの性能に対して、出荷時初期値である 1M バイトはかなり小さいので、性能を引き出す為に割り増します。 | ||
準備が出来たら、アンロードを開始します。
画面表示から次の情報を得ました(一部を抜粋)。
出力バイト総数(kbytes) : 58743007.17 所要時間(秒) : 604.77 処理速度(kbytes/秒) : 97132.80
パフォーマンスモニタから次の画像データを得ました。
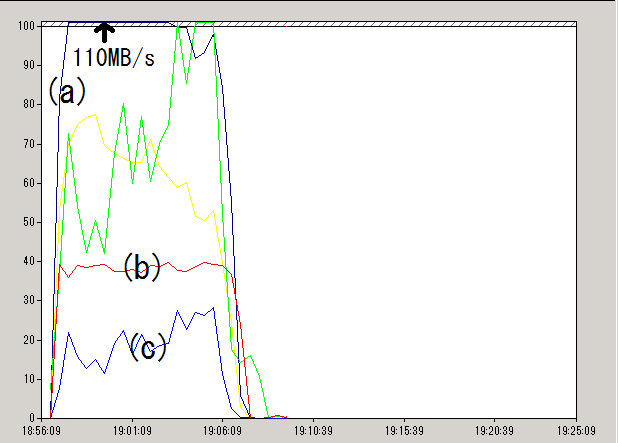
実験3のパフォーマンス・モニタ画像
ヒープ構成表の並列アンロードは、大量データに起因する性能問題の一部を和らげる効果があります。しかしパーティショングのような根本的解決を目的とするものではありません。一言で言えば適用分野が限定的なので、どのようなケースでも応用できると過信すると却って重いシリアル化を招き、期待通りの効果を発揮出来ない事があります。
とは言え、実験で用意したようなデータ量に著しい偏りのあるスキーマを対象とした場合、コンピュータ・リソースのアイドル時間を大幅に削減できるので、てきめんに高い効果を発揮するはずです。
ライセンス費用負担が重い Enterprise Edition や Partitioning option へ移行しなければならない程、性能問題が深刻でない読者はまずこの機能に触れてみる事をお奨めします。
そして、シングル・スレッド・プロセスであるオリジナル・エクスポートや、並列操作が Enterprise Edition だけに制限されている Data Pump Export といった著名なデータ移行ツールと MTU の何が違うのかを読者ご自身の手でお確かめ下さい。
MTU は1ヶ月間の無料評価ライセンスを用意していますので、どなたでも手軽にダウンロードして費用対効果を検証する事が出来ます。
by 開発1号