尚、記事の内容は 3 年以上のプログラミング経験のある読者を対象としています。
120210401 $ 3A203-00845012-100085521-230329395042004132832 $ 4001NW104P 乾電池 単三型 4本パック 000000230000001$ 4002ACN-8500 空気清浄機 000042800000001$ 4003LCN-KS500 取替用LEDランプ 13W 000001200000003$ 4004BP-50K 交換用紙パック20枚入 000000700000002$ 3A203-00846005-10003A058-002329395023002165402 $ 4001YPH-862 イヤホン(黒) 000002500000001$ 4002KBL-5M LANケーブル 5m 000000580000001$ 900008 $
| データ属性 | ホスト | オープン | |
|---|---|---|---|
| 文字列 | 半角英大文字 ・数字・記号 |
EBCDIC | JIS X 0201 (ANKコード) |
| 半角カナ | EBCDIC(caps off) | ||
| 日本語 | IBM漢字コード,JEF,JIPS | Shift-JIS | |
| 数値 | パック/ゾーン10進数 | ASCII | |
| 項目番号 | 1 | 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| 項目名 | 区分 | 作成日付 | ||||||
| ヘッダ・レコード | 1 | 20210401 | ||||||
| 伝票 #1 |
項目番号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 項目名 | 区分 | 伝票番号 | 売場 | 担当職番 | 顧客ID | 明細数 | 時刻 | |
| データ・レコード (伝票) |
3 | A203-00845 | 012-10008 | 5521-2303 | 29395042 | 004 | 132832 | |
| 項目番号 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| 項目名 | 区分 | 明細番号 | 商品コード | 商品名 | 単価 | 数量 | ||
| データ・レコード (明細) |
4 | 001 | NW104P | 乾電池 単三型 4本パック | 000000230 | 000001 | ||
| 4 | 002 | ACN-8500 | 空気清浄機 | 000042800 | 000001 | |||
| 4 | 003 | LCN-KS500 | 取替用LEDランプ 13W | 000001200 | 000003 | |||
| 4 | 004 | BP-50K | 交換用紙パック20枚入 | 000000700 | 000002 | |||
| 伝票 #2 |
項目番号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 項目名 | 区分 | 伝票番号 | 売場 | 担当職番 | 顧客ID | 明細数 | 時刻 | |
| データ・レコード (伝票) |
3 | A203-00846 | 005-10003 | A058-0023 | 29395023 | 002 | 165402 | |
| 項目番号 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| 項目名 | 区分 | 明細番号 | 商品コード | 商品名 | 単価 | 数量 | ||
| データ・レコード (明細) |
4 | 001 | YPH-862 | イヤホン(黒) | 000002500 | 000001 | ||
| 4 | 002 | KBL-5M | LANケーブル 5m | 000000580 | 000001 | |||
| 項目番号 | 1 | 2 | ||||||
| 項目名 | 区分 | 件数 | ||||||
| トレーラ・レコード | 9 | 00008 | ||||||
各レコード定義書を提示します。項目名にある「FILLER」とはレコード長を揃える為の詰め物です。
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
回り込みが解除用のタグ

回り込みが解除用のタグ
| 入力元ファイル名 | 出力先ファイル名 | 種類 |
|---|---|---|
| [path\to\]name.ext []内省略可能 |
第2引数\name_1.csv | ヘッダ |
| 第2引数\name_3.csv | 伝票ヘッダ | |
| 第2引数\name_4.csv | 伝票明細 | |
| 第2引数\name_9.csv | トレーラ |
回り込みが解除用のタグ
sample_1.csv "区分","作成日付" "1","2021-04-01" |
sample_3.csv "区分","伝票番号","売場","担当職番","顧客ID","明細数","時刻" "3","A203-00845","012-10008","5521-2303","29395042",4,"13:28:32" "3","A203-00846","005-10003","A058-0023","29395023",2,"16:54:02" |
sample_9.csv "区分","件数" "9",8 |
sample_4.csv "区分","伝票番号","明細番号","商品コード","商品名","単価","数量" "4","A203-00845",1,"NW104P","乾電池 単三型 4本パック",230,1 "4","A203-00845",2,"ACN-8500","空気清浄機",42800,1 "4","A203-00845",3,"LCN KS500","取替用LEDランプ 13W",1200,3 "4","A203-00845",4,"BP-50K","交換用紙パック20枚入",700,2 "4","A203-00846",1,"YPH-862","イヤホン(黒)",2500,1 "4","A203-00846",2,"KBL-5M","LANケーブル 5m",580,1 |
cd /d 移動先フォルダ名
MSBuild MfFixed2Csv.sln -m -verbosity:minimal -target:Build -property:Configuration=Release
.NET Framework 向け Microsoft (R) Build Engine バージョン 16.9.0+5e4b48a27
Copyright (C) Microsoft Corporation.All rights reserved.
MfFixed2Csv.cpp
MfFixed2Csv_Impl.cpp
コード生成しています。
267 of 450 functions (59.3%) were compiled, the rest were copied from previous compilation.
17 functions were new in current compilation
21 functions had inline decision re-evaluated but remain unchanged
コード生成が終了しました。
MfFixed2Csv.vcxproj -> C:\Users\demo_user\Source\Repos\MfFixed2Csv\x64\Release\MfFixed2Csv.exe
x64\Release\MfFixed2Csv.exe MfFixed2Csv\sample.dat %TEMP%
The data before conversion will be read from MfFixed2Csv\sample.dat and written to C:\Users\demo_user\AppData\Local\Temp after conversion. Selected records (3)=2, rec size=62 Selected records (4)=6, rec size=62 Total records=10
C:\Users\demo_user\Source\Repos\MfFixed2Csv>where $TEMP:*.csv C:\Users\demo_user\AppData\Local\Temp\sample_1.csv C:\Users\demo_user\AppData\Local\Temp\sample_3.csv C:\Users\demo_user\AppData\Local\Temp\sample_4.csv C:\Users\demo_user\AppData\Local\Temp\sample_9.csv
共用体と呼ばれるデータ型を利用します。当サンプルでは「LAYOUT」とタグ付けされた共用体を使います。共用体はデータ型の一つで、同じメモリ領域を複数の型が共有する構造です。
右は当サンプルの MfFixed2Csv/MfFixed2Csv.h を一部を例示していますが先頭にLAYOUTがあります。
この共用体には、char line_buff[]、REC1 r1、REC3 r3、REC4 r4、REC9 r9、の合計 5 つのメンバーが含まれています。
共用体では同じメモリ領域を複数の型が共有しますので、例えば line_buff へ固定長ファイルから読み取られたデータが 展開されると他のメンバーも直ちにその内容を参照できます。
読み取り場所をそのまま他で参照する場所としても利用できるので、追加のメモリ領域を必要としない上、コピーも不要いうメリットがあります。
回り込みが解除用のタグ
例えば LAYOUT に属するメンバーのひとつ、REC3 という型の定義はどうなっているか確認してみましょう。これは LAYOUT よりも前方に定義されています。
項目 C02 ~ C08 までの 7 つの項目は売上伝票のヘッダ部分にあたる項目をそれぞれ表していて、char配列の要素数(大カッコ内の整数)は、ファイル定義書中定義された長さを基に決めます。例えば担当職番がPIC X(09)という定義であれば、char配列の要素数は9、あるいは明細数がPIC 9(03)という定義であれば、char配列の要素数は3とします。
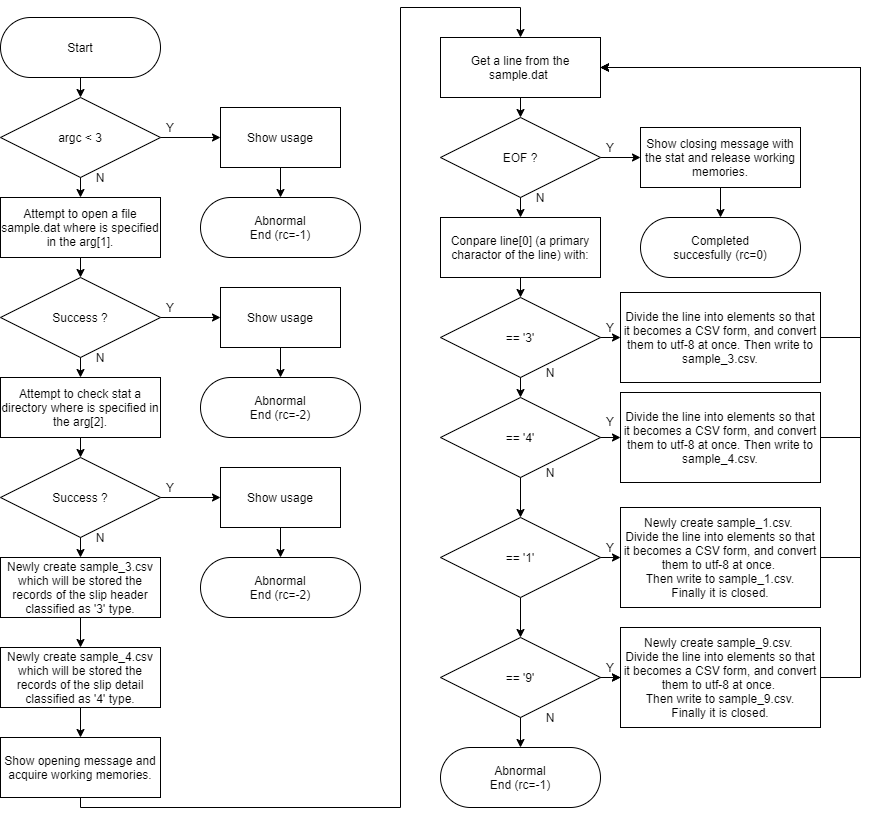
読み取ったデータが、伝票ヘッダに該当する事は、項目 C01 (区分)の値に ‘3’ が与えられている事で判別します。8つの項目をすべて合わせると、合計62バイトになりますがこのバイト数が、line_buffへ展開されるデータの長さと同じになります。
line_buff への固定長データ展開はどこで行われているかというと、MfFixed2Csv/MfFixed2Csv.cpp の 118 行目にあります。ifstream クラスのメンバー: getline を呼び出して、その引数として unifiedという変数のメンバー: line_buff のアドレスを渡しています。
getline 関数がリターンすると line_buff には読取データが展開されています。しかし、このステップでは、展開されたデータがどの区分のレコードなのか判別できていません。
後続のステップ(右側の枠線内)で line_buff へ展開されたデータの1バイト目を区分として扱い、各区分に応じた固有の処理を行う過程が 124 行目から続く多枝分岐に書かれています。ここまで到達すると共用体:LAYOUT のメンバとして定義されている REC1, REC3, REC4, REC9 の各構造体に当てはめた処理を開始できることになります。
もし、共用体を使わずに同じ処理を書こうとするとどうなるのでしょうか。line_buff に展開されたデータを、個別に受け取るバッファーを REC1, REC3, REC4, REC9 の各構造体毎にひとつづつ用意し、line_buff の複写をとる必要が生じます。つまり左側の枠線内のようなコードを書かなければなりません。これは、スマートな実装とは言い難い上に memcpy 関数を何回もコールするので右枠線内のコードと比べると追加の待機時間が発生します。
........
REC1 r3;
REC1 r4;
........
ifs.getline(unified.line_buff, BUFFER_SIZE);
........
switch (line_buff[0])
{
case '3':
::memcpy(&r3, &line_buff, sizeof(r3));
ofs_h << r3.output_body(
........
case '4':
::memcpy(&r4, &line_buff, sizeof(r4));
ofs_b << r4.output_body(
........
ところで case '1', case '9' よりも case '3', case '4' の分岐先コードブロックを、先に書く理由は分かりますか?
'1'と'9'は、for ループ文の内側にあるものの、プログラムの存続期間を通じてそれぞれ1回ずつしか実行されないからです。
case 文に並ぶ各分岐先は先頭のものから順にマッチするかどうかが確認されますので、より多くのレコードが存在するであろう、区分 '3'及び'4'を優先して比較するには処理効率上の意味があります。
回り込みが解除用のタグ
ソースコード MfFixed2Csv/MfFixed2Csv.h の 82 行目にある adapt_numeric という関数テンプレートで、この処理を行っています。
引数の dst は四則演算が可能な short, int, long, int64_t などの整数型を総称する為、型をテンプレート引数に代えて適用しています。ここに第2引数の src から読み取った整数データが格納されます。冒頭部分にある for ループで、数値文字列の全体長 -1 回分だけ繰り返し処理があります。
繰り返す内容は dest へ現在格納済みのデータを 10 倍し、src から読み取った次の1文字の数値を足しこむ、というものです。「*src++ - '0'」は何をする処理かというと、読み取ったASCII文字から数量を抽出しています。"++" は src というポインタ変数が指すアドレスを1つ分上位へ移動させるという意味で、数量抽出の後に実行されます。
ASCII のコード定義を見ると、'0' から '9' までの文字は 0x30 から 0x39 までのコード値が順番に割り当てられている為、'0' を第 2 項へ置いて算術的な引き算をすると、'0' からのコード表上の距離がそのまま数量として導き出すことが出来ます。C言語の経験がある方は atoi() というライブラリ関数を使えばもっと分かり易いのに、とお思いになるかもしれませんがここではあえて使いません。
一般に関数呼び出しは CPU コストが掛かる処理とされている為、プログラム中で大量に呼ばれることがあらかじめ分かっている場合は、このように当該ライブラリ関数で実行されている内容に等しいコード中をベタ書きして最適化を図る場合があります。
for ループ文の後に続く if else 文は、固定長文字列 "s" の最後の1文字に対する処理となります。ホストから変換済みのデータを受取った時に、数値表現がすべて符号無し10進数: "PIC 9(桁数" であれば、(*src < 0x40) の条件内のブロックですべて処理されます。
そうではなくて符号付き10進数: "PIC S9(桁数" を受取った時に、正しく数値変換が出来るよう (*src < 0x4a) 以下の条件が用意されています。
下の表は、符号付き10進数の最小桁にあてがわれる文字の全バリエーションと文字コードの関係をまとめたものです。符号付き10進数を表した固定長文字列の正負符号はこの1文字で決定されます。数値 0 を表す文字が、EBCDIC では数値 1 と連続している(C0→C1,D0→D1)のに対して、ASCII ではコード表上のいわば飛び地に置いてある(7B→41,7D→4A)ので、プログラムが少し読みにくくなっています(後方2つの else if 文)。
| 正の値 | 負の値 | ||||||
|---|---|---|---|---|---|---|---|
| 数値 | EBCDIC | 文字 | ASCII | 数値 | EBCDIC | 文字 | ASCII |
| +0 | C0 | { | 7B | -0 | D0 | } | 7D |
| +1 | C1 | A | 41 | -1 | D1 | J | 4A |
| +2 | C2 | B | 42 | -2 | D2 | K | 4B |
| +3 | C3 | C | 42 | -3 | D3 | L | 4C |
| +4 | C4 | D | 42 | -4 | D4 | M | 4D |
| +5 | C5 | E | 42 | -5 | D5 | N | 4E |
| +6 | C6 | F | 42 | -6 | D6 | O | 4F |
| +7 | C7 | G | 42 | -7 | D7 | P | 5G |
| +8 | C8 | H | 42 | -8 | D8 | Q | 5H |
| +9 | C9 | I | 42 | -9 | D9 | R | 5I |
adapt_numeric 関数から戻ると、変換されたデータは整数型としてバッファーへ保存されます。サンプルプログラムではMfFixed2Csv/MfFixed2Csv_Impl.cpp の 300, 322, 325, 326, 346 行目にその呼出しがあります。
保存されたデータは後続の 310, 332, 335, 336, 351 行目で参照されます。これらは後続の snprintf というライブラリ関数の呼出し引数として与えられています。同じく引数として与えられる書式化文字列で "%d" に適合するようデータが書式化されるので前詰めゼロ値が取り除かれます。
前詰めゼロを取り除く、という直接的な操作を行う代わりに、整数型を書式付きで出力する事で結果的に取り除いたことになります。
ここで特に留意して頂きたいのは snprintf の呼び出し回数を 1 に抑える、という事です。実際の固定長形式ファイルでは項目数が数百以上にも及ぶケースがあるので、一般には保守を容易にする為 snprintf を項目数だけ繰り返し書くことになります。しかし移行用途のプログラムは保守が容易であることよりもパフォーマンスが重要なので前にも触れた通り関数呼び出し削減を徹底してください。
回り込みが解除用のタグ
例えば Microsoft Excel の場合だと、セパレーター無しで作成日付の "20210401" を読み取らせても、8桁の整数として扱われてしまい、日付固有の演算が出来ません。例えば翌月末の日付や、他の日付との間に何日のインターバルがあるかを求めるのに整数では不適当です。
データを移行した先のアプリケーション上で正しく日付時刻を扱う為には、インポートされる前に年・月・日、および時・分・秒の正しい区分けが出来ている必要があります。
当サンプルでは、この処理を行う為の関数として adapt_date() と adapt_time() がそれぞれ MfFixed2Csv/MfFixed2Csv_Impl.cpp 上に用意されています(188 行目と 213 行目)。
これらは詳しく説明する必要が無いほどシンプルな実装ですが欠かせない存在です。
回り込みが解除用のタグ
連続する半角空白と全角空白文字を固定長データの末尾から取り除く処理: adapt_varchar() が MfFixed2Csv/MfFixed2Csv_Impl.cpp 上の239 行目に用意されています。
同じ空白のように見える文字でも、半角と全角では構成バイト数や操作用コードが異なるので if else 文を使って選り分けています。else 句には、取り除き対象でない文字をコピーする為の処理です。
removing というフラグは、文字列中に含まれるデータとしては有効な空白が取り除かれないようにする為にあります。
関数の戻り値として扱っている wlen は取り除き対象として認識された最後の空白文字があった場所を記録している為、結果的に残された文字列の長さを示すことになります。
回り込みが解除用のタグ
当サンプルでの外部キーは伝票番号です。伝票番号が読み取られるのは、区分 '3' のレコードが読み取られた時です。反対に伝票番号が引用されるのは区分 '4' のレコードが読み取られた時です。こちらの処理は REC3::output_body() と REC4::output_bodyが MfFixed2Csv/MfFixed2Csv.cpp 上の 124 ~ 135 行目に用意されています。
PK_REC3型の pk という名前の変数が媒介となって、伝票番号を REC4 型の変数へ引き渡しています。
回り込みが解除用のタグ
UTF-8 への文字エンコーディング変換は何回も繰り返し使うので、クラスを用意して部品化しています。クラス名は Converter といい MfFixed2Csv/MfFixed2Csv_Impl.cpp 上の 112 ~ 148 行目に実装が用意されています。
static な記憶クラスで宣言された SjisToUtf8 という関数の引数に Shift-JIS でエンコードされた文字列を与えると、UTF-8 への変換が行われ、関数の戻り値として UTF-8 が戻されます。
意外なことに、Shift-JIS から直接 UTF-8 へ変換する為の手段は 標準テンプレート・ライブラリ(STL) に用意されておらず4 OS ベンダーが提供する API か C 標準ライブラリを組み合わせて実現する方法しかありません。当サンプルの場合は、ホストからデータを受取った時の前提として Shift-JIS (つまり Windows での利用)を想定しているので Windows の API である MultiByteToWideChar()、WideCharToMultiByte() とを使います。この API をそれぞれ 2 回ずつ実行して、Shift-JIS → UTF-16LE → UTF-8 の段階を経て変換します。
1度目の API 呼出しは変換結果を受け取る側の引数に 0 を与え、確保するのに十分なメモリサイズを事前に求めています。こちらで求めたサイズのメモリを後続の処理で確保しますが、メモリの割り当てと解放は頻繁に行われると最大の待機原因になるので、今まで確保した事のある最大のメモリを超えた場合のみ、改めて確保し直すというロジック5にして、再割り当てが最小限度に抑えられるようにしてあります。必然的にこのオブジェクトは、プロセスの存続期間中ハイ・ウォーター・マークを保ち続けなければならないという理由と、マルチスレッド化で更なる性能強化を図れるようにするための準備6として、Singleton パターンでオブジェクトを実装しています。Convert::SjisToUtf8 関数が static な記憶クラスになっているのはその為です。
一方、CSV ファイルを BOM 付きにする為の仕掛けは、Converter::bom という static な符号無し8bit整数の配列を、オープン直後のファイルへ出力する事で実現しています。こちらのコードはMfFixed2Csv/MfFixed2Csv_Impl.cpp 上の 150 ~ 179 行目に実装されています。
回り込みが解除用のタグ
by 開発1号